Privacy Preserving
Overview
Protecting data privacy is challenging, there is no “one-fits-all” privacy approach. Choosing approach depends on:
- Intended data use
- Accuracy constraints
- Performance constraints
- Adversarial model
The AMIS Privacy Framework is a comprehensive framework that encapsulates most prominent privacy models:
- Syntactic models (generalization/suppression)
- Semantic models (differential privacy)
- Cryptographic models (searchable encryption)
The framework supports a diverse set of data uses (e.g. operations, statistics, data mining)
Functionality Overview
- Online
- operates on streaming data
- high-throughput, limited accuracy
- Offline
- queries repository with historical flow data
- complex strategies for increasing accuracy
Online Mode
This mode is suitable for network monitoring tasks. The users register for continuous queries and the flow data are generalized and streamed to users. In this case we are using k-anonimity for online anonymization of the streams. We receive continuous streams from a RabbitMQ exchange, the main thread of our program receives the streams by connecting to the exchange. We use Hilbert sorting (calculate a Hilbert coordinate for each data stream), then we anonymize the streams in buckets that present the same characteristics (each bucket has between k and 2*k-1 -values) and present the user with those buckets.
Offline Mode (Differential Privacy)
The offline mode implements the popular Differential Privacy (DP) protection model, and is suitable for Netflow analytics, data mining task and statistical queries on top of the network flow dataset. Differential privacy has become the de-facto standard for privacy-preserving data publishing in the past few years. It has been adopted by many government organizations, as well as major industry players, such as Apple, Google and Mozilla.
A differentially-private data interface allows users to issue aggregate queries (e.g., COUNT, SUM, AVG), and adds random noise to the results in order to achieve privacy. Specifically, the privacy objective of DP is to prevent an adversary to learn whether a particular flow is present in the database or not. In practice, this translates in the inability of an adversary to learn if a targeted individual (e.g., user of a computer with a given IP address) has visited a particular website, or connected to a certain service.
A central concept of DP is that of sibling (or neighboring) databases. Two databases D1 and D2 are siblings if they differ in exactly one record. Given a randomized mechanism R that answers queries on top of a database, DP guarantees that by inspecting the output of mechanism A, an adversary cannot learn with significant probability which of the datasets D1 or D2 has been used to answer the query. Formally,
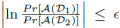
The parameter ε is called privacy budget. A smaller value of ε corresponds to a more stringent privacy constraint. In practice, it ranges in value between 0.1 and 1.0. In order to achieve DP with parameter ε, the Laplace Mechanism (LM) adds to each query result randomly distributed noise according to a Laplace distribution with mean 0 and variance S/ε, where S is the query sensitivity. Intuitively, sensitivity measures the amount of overlap of all issued queries. To obtain better accuracy (i.e., less noise), it is important to reduce the amount of overlap.
In our system, we provide a differentially-private processing engine on top of a Big Data repository. Flow data is stored outside in a HBase data center, indexed according to several keys, in order to efficiently support several query types (e.g., time-based, IP range-based, port-based, etc). We use Hadoop to query the repository and pre-compute data summaries called contingency tables. These tables have Laplace noise added to them, and at runtime, when users issue queries, the contingency tables are used to retrieve the results. This approach allows us to be more efficient (summary tables are smaller in size), and also to control the amount of overlap, hence improved accuracy.
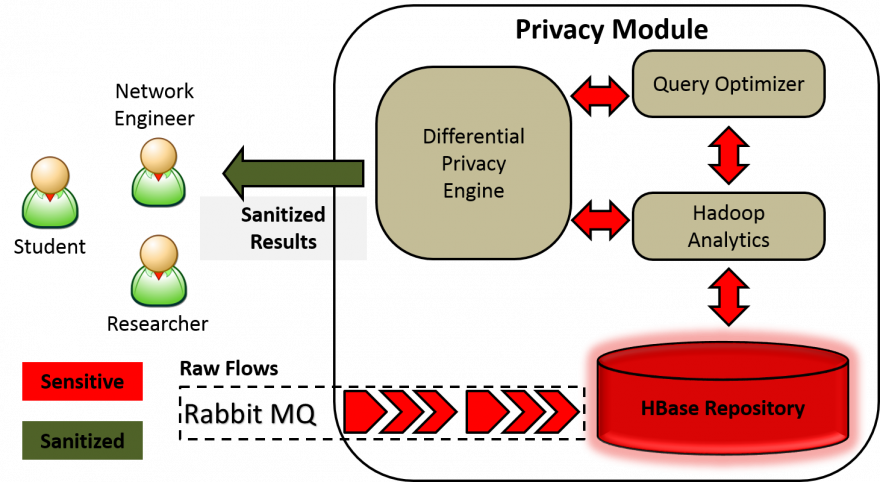
The diagram above shows the flow of information in our system: the red flows correspond to non-private data, whereas the green flows represented sanitized data that can be shared with the users. We collect netflow data from RabbitMQ queues which are populated at Internet2 Exchanges using the tool developed by our partners at UML. We index the net flows into our HBase raw table. Hadoop jobs periodically query the raw data and build contingency tables, also stored in HBase. Several criteria can be used for aggregation, such as time, IP range, port range, protocol number. At run time, users submit their queries through a REST interface to our front-end server, which in turn parses the queries and submits them to the HBase cluster. The noisy (i.e., sanitized) query results are then returned to the user.
NetFlow Schema
The NetFlow Protocol Version 9 standard developed by Cisco provides a representation of a network flow called a flow record, containing a number of fields describing the traffic [CISCO]. NetFlow v9 defines over 100 field types, but only a few are needed for our use case. We receive flows in the form of export packets (diagram shown in Figure 3.1) from various routers on the Internet2 network, and extract the necessary fields for collection. It is possible for export packets to contain multiple flow records, as well as various templates dictating what fields to extract from the record.
The NetFlow attributes to be collected into HBase are:
| Field Type | Length(bytes) | Description |
|---|---|---|
| IN_BYTES | 4 | Number of incoming bytes for a network flow |
| IN_PKTS | 4 | Number of incoming packets for a network flow |
| IP_PROTO | 1 | IP protocol associated with the flow (i.e. TCP, UDP, ICMP, etc.) |
| PORT_SRC | 2 | TCP/UDP Layer 4 source port |
| IP_SRC | 4 | IPv4 source IP address |
| PORT_DST | 2 | TCP/UDP Layer 4 destination port |
| IP_DST | 4 | IPv4 destination IP address |
| OUT_BYTES | 4 | Number of outgoing bytes for a network flow (we compute this) |
| OUT_PKTS | 4 | Number of outgoing packets for a network flow (we compute this) |
Besides the above attributes we also save the “stamp_inserted” attribute of the flow in HBase.